The dummies guide to integrating LLMs and AIs into EHRs, Part 2: The intersection of data, time and users.

If you haven’t read part one, check it out here:

Thinking about decision making and output

Recently it was my first wedding anniversary with my wife. As is tradition, I went to the store to purchase Molly a gift to celebrate the occasion. While looking at various stylish paper products, I needed to take the following inputs to make a decision:
How long I’ve known her and what would she like: We’ve been together for a long time and I have a good idea of her tastes, aesthetic and what she generally likes and dislikes. If she was laying any hints for me recently, I would want to pick up on them.1 I also need to ensure that I take recent gifts into account so that I don’t buy her something identical to what I have purchased her previously. It feels weird to call this input data, but it is data.
Where should I get the gift? Molly generally likes home interior stores and tiny stores with a warm aesthetic, but I suppose if I needed to I could have cast a net as wide as every store at the mall next to where I work.2
When should I give her the gift? It was our anniversary, so I needed to provide it to her that day. If I provided it beforehand it would have been too early and would have diminished the sentimentality. If I provided it late, it would have lacked the desired intent.
What should I do afterwards? Molly enjoyed it so I knew that I did a good job.3 Mission accomplished. If I had gotten Molly something she did not want or that she thought was inappropriate I imagine I would have found out.
As abstract as it may seem, medical decision making at the intersection of data and clinicians is not much different than this gift purchasing example. To use data to make a good recommendation to a clinician, you must ask and answer the following questions:
How much data do I need? How do I weigh it? How do I handle new inputs?
Where should my model pull data from?
What is the workflow for clinician interaction?
How do you know if the model was effective?
How much data do I need? How do I weigh it? How do I handle new inputs?
Prior to fully digitized medical records, how much data someone needed for medical decision making was straightforward due to constraints. Barring your PCP or specialist remembering a patient and their case, the doctor had the data in their chart and as much preparation as they put in to determine how to treat them. But now with decades of digital records clinicians can make informed decisions based on years of knowledge. However, just because there is decades of data does not mean that it should be processed it in order to make a decision. First, it may provide outputs that are not currently relevant to the situation. If I am a patient and I just tore my ACL, it may not be the best time to ask about a slightly elevated lab that I had 4 years ago which has not been abnormal since. Second, processing data takes time and involves ingesting all of that data. HIPAA and other regulatory controls have minimum necessary standards and covered entities may be sensitive to the amount of data which they distribute to other systems. This is especially true if that data is not used to improve patient care. Third, even if there is a bunch of historical data, the output may need to be based on the patient’s current status. While it might be appropriate to take historical data into account, the model may only need inputs based on what is happening now. If a prescribing clinician just received an alert for a potential drug/drug interaction, the alert doesn’t need to incorporate all medications taken by the patient ever to know that the interaction is problematic and to the extent it should warn the clinician. It just needs a current medication list.
As such, much like deciding which gift my partner would like, the matrix of decisions when pulling data for decision involves the tradeoff of “how much data do I need”, “how much time do I have to get it”, and “is new data (even data just provided to the computer) more important than old data”.
Let’s run this through some scenarios:
TranscriptionBot:
Our first classic LLM scenario is what I will call TranscriptionBot. TranscriptionBot listens to a dictated note or overhears a clinician and a patient during their exam. It takes the audio, transcribes it using a technology like Amazon Comprehend, transforms it into data objects and structures, and it outputs the core outcomes of the exam (structured SOAP note, problem list, follow-up, pending orders and medications) back into the EHR. The model was trained on a corpora of exam notes for recommended decisions based on pertinent clinical guidelines and by recommending a note which looks like it was written by a clinician.
How much data do I need? TranscriptionBot at instantiation needs to process the audio from the exam. However, when writing data back into the EHR, TranscriptionBot requires pulling any historical data objects intended for the EHR to ensure non-duplicate data (or placing this decision making back onto the clinician). For example, if the patient tells you they are taking ranitidine in the exam you’d rather not document two ranitidine prescriptions in the medication list that are similar.
How much time do I have to get it? It depends. If TranscriptionBot allows the clinician to finish writing the note while in the patient exam room, it needs to be pulling any clinical data during the clinician’s exam. This assumes that the bot can transcribe and parse the audio synchronously as well. This was the key difference between “old DAX” and “new DAX”. Remember that this data may change between pre-appointment and the exam by the clinician. A nurse may update medications or the patient’s history. So, fresh data here is paramount.
Is new data more important than old data? No, unless the bot delegates all reconciliation to the user (which, would be less useful than a human scribe). The bot must reconcile both historical data and new data to be effective.
InboxBot:
InboxBot is an model that is instantiated every time that a doctor or APP receives an message through their patient portal. The model was trained on millions of Inbox messages and merged with the trained model of MaryPoppinsBot to be overwhelmingly positive in response. Once instantiated, InboxBot then does three tasks:
The bot pulls pertinent patient information including their basic data (hx, problem list, meds, recent orders), the outcomes of their last office visit or admission and any upcoming appointments.
The bot analyzes the incoming message for both its query and its sentiment (is this a negative message or not? how much do you think they will wait without sending this further up the chain?)
The bot then either:
Encourages the patient to go to the urgent care or seek emergency treatment (and informs a triage nurse to coordinate this ask)
Encourages the patient to wait until their next appointment to be treated.
Triages the request to the doctor/APP’s support team to handle the request (schedule an appointment, reassure the patient, etc).
Triages the request to the doctor with a pre-written draft to the patient with prompts for medical decision making (e.g. you sent me a picture of this rash and InboxBot can’t interpret photos, but I looked at the photo and the rash should only require OTC hydrocortisone). In this case it also creates the encounter and any pertinent charges for the provider’s time.
Automatically responds with information it has access to. If the patient asks “what do I need to bring to my next appointment” it can read the instructions for their next appointment and respond with them to the patient.
How much data do I need? The bot pulls pertinent patient information including their basic data (hx, problem list, meds, recent orders), the outcomes of their last office visit or admission and any upcoming appointments.
How much time do I have to get it? Not critically, but also not forever. The application can queue all these requests and process them as they come.
Is new data more important than old data? The new data is ingested by the model but it does not need to incorporate any additional input from the clinician to operate. It is mostly making decisions based on old data.
CxrDecisionBot
CxrDecisionBot is an model that determines when a chest x-ray is appropriate to order. Taking the inputs of the chief complaint, triage notes and any exam information from the doctor/APP, the bot then indicates via clinical decision support whether or not the clinician should order/perform a lung ultrasound or if the clinician should order a chest x-ray. The model was trained on a corpora of notes where a chest x-ray was the sole diagnostic along with clinical guidelines to provide a better tuned recommendation engine on chest x-rays to ensure that the particularities of a patient and clinician are considered when making the recommendation.
How much data do I need? No historical data is pulled. Only the current information for the patient as they present is pulled.
How much time do I have to get it? The data must be pulled between the exam and when order entry is performed.
Is new data more important than old data? Yes. We don’t care that much about old data here and the algorithm is basically checking to ensure that new data doesn’t indicate one of the appropriate use cases for a chest x-ray.
Wrapping up pulling data and moving on
The data access patterns of various AI models change based on their use cases. None of these bots are pulling data or even share instantiation points. As you think through your own use cases, thinking of the data required and the inflection point upon which the model input and output is instantiated will guide you towards the best use case for your application.
Where should my model pull data from?
Technically speaking, a model doesn’t have to pull data from anything. If the model takes the user’s voice/note and makes it “better” and relies on the user to schlep it around into the EHR, the app requires zero integration. This makes sense in situations where integration is either impossible or prohibitively expensive or complicated.4 However, it seems like most models are relying on some variety of integration at this point. While these products may have a “no integrations” option, like we discussed in part 1, these businesses likely understand that their integration not only leads to their adoption and stickiness but also the virtuous cycle of improvement (how do you refine the model if you don’t inherently know what a user kept from your recommendations?).
However, it is worth noting that in the John Henry-esque man vs. machine race of virtual scribes to human scribes, a human wins at thinking creatively about data acquisition. If during workup on a patient a scribe noticed a patient’s appointment was a follow up from an ED Admission but the admission wasn’t in the chart since it was part of another health system/EHR, the scribe could either pull the data using whichever chart sync tools are available via their EHR or by picking up the phone and trying to get the information faxed to them. Does this always happen? No. But it could.
As such, much like a human, a virtual scribe should be ensuring that it understands the problems it is solving and understand if pulling data from interoperability frameworks like Commonwell/Carequality via any handful of integrators (redox, health gorilla, etc.). If the goal of the decision making is completeness, especially in handoff situations in value-based scenarios, then pulling data from multiple data sources and reconciling it for users may prove to be extremely important in practice.
InboxBot from above is a good example of a model which could benefit from enhanced inputs. If a patient asked about a follow-up from an admission and InboxBot can’t find a recent admission in the record when querying its own EHR, it might make sense for InboxBot to pull data beyond that of its own walls to see where the admission occurred and what happened during that decision to help the staff make better decisions.
What is the workflow for clinician interaction?
An EHR is software which drives two main purposes:
Workflow
For a given encounter, perform these steps to complete the visit/admission. This is what good care looks like.5
Compliance
There are rules the health system has to follow lest to avoid scrutiny from the Joint Commission, Payers, State Boards, Litigation, etc. etc.
This is the topic by which most LLM/AI tools seem to be glossing over. Basically, how much do people need to know about your bot? However, this is what I believe actually has some of the most complexity in integrating these tools. If there were a spectrum that was roughly:
← →
“Bot doesn’t exist” “Bot is named on CareTeam”
Notably, within three aspects:
If an AI-based model assists a clinician with a medical decision, should that get documented in the chart? Do other clinicians need to know the calculus by which the decision was made or does this only need to be stored internally in the event of an audit.
If the AI-based model is documented in the chart, how do fellow clinicians at the same organization know that a given output was written by a bot? This occurs to some extent whereby external applications write data into EHRs today via “system users” and other tools, but transparently nothing is providing as much simulacrum to a clinician as generative AI tools purport or are anticipated to provide as they both improve and demonstrate their safety.
Depending on the output of the algorithm, do other users need to know that you ignored the recommendation and why? How does that present itself to other clinicians?
These questions are not new and just as easily apply to traditional care pathways and algorithms. However, as we pull closer towards the human equivalent of documentation via generative AI models, these lines will blur. Heck, even traditional human documentation on “what data should live where in which systems” is often contentious and involves the most flexibility from any vendor at scale.6
Once you determine transparent your bot must be, the next question should be where in the workflow should the data present itself? Put flatly, if the output of your model cannot inform timely decision making consistently it’s useless.7 It can predict or ascertain objectives saliently but if you can’t interject correctly into workflow (both technically and culturally) then the tool is no good.
The ways the output of a model can present themselves generally breaks down into a few options, broken into quadrants.
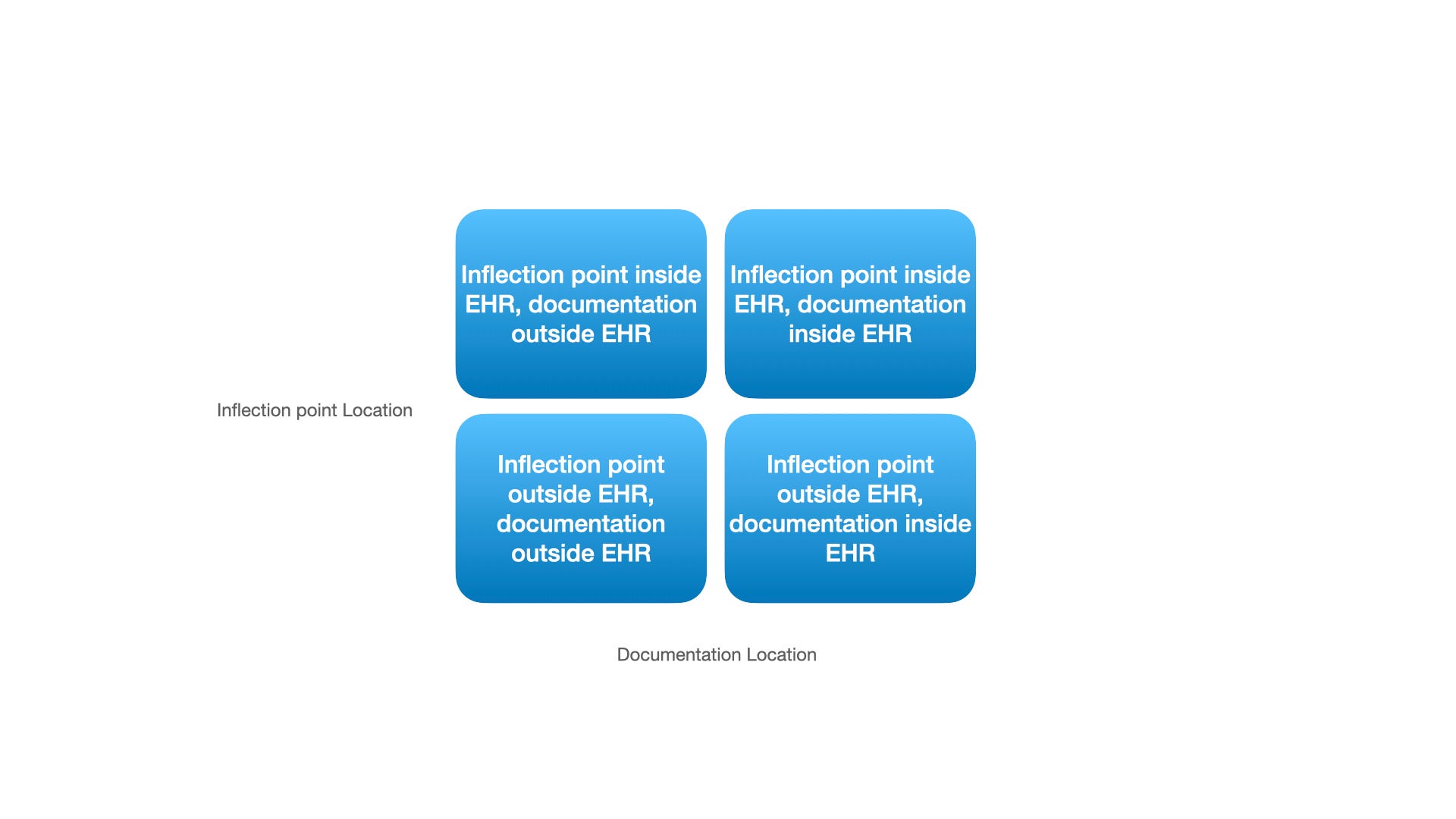
Inflection point: Where does the clinician find out that the model was evaluated or invoke the model? Is it inside the EHR or outside the EHR? Examples of EHR internal inflection points are generally things like EHR notes, provider inbox messages and clinical decision support hooks. External inflection points are in stand alone apps or interactions outside the EHR that may notify the provider of an event. For example a care team receiving a secure message that their patient is at risk for sepsis. Or using Viz.ai for care coordination, with downstream data ending up back in EHR based on recommendations.
Documentation location: If the model outputs clinical decision making, does that data end up in the EHR? Can the bot write a progress note? Can it place orders? Does it tell the doctor to do something by creating an Inbox message? Is it making recommendations or can it perform some tasks directly per protocol? Or can it remain externally in another system?
Of course, looking at it on the face of things, every application would prefer to be fully integrated bi-directionally if it came down to it. However, to paraphrase the Notorious B.I.G., Mo Integrations, Mo Problems. It raises the cost of products and their time to implementation. If someone buys a Butterfly IQ+, they can begin scanning patients immediately.8 If they want bi-directional EHR and PACS integration it takes approximately three months to do. Workflow assistance models are no different. Perhaps obviously, if an app needs to read provider inbox messages it need some type of data integration. But a great app ideally works without data integration and demonstrates it value and has a progressive path to more integration. Understanding where to prioritize integration roadmap items lies in the basic value prop of the application.
If the goal of the product is to provide a valuable insight and have clinicians react to it, then fully integrating with the right inflection point at the right time is more critical than complete loop documentation. Yeah, a provider can pull up the app on their phone and type in some data and see if the AI decides something should happen or not. If the organization has a culture of standardization (e.g. Mayo Clinic clinicians know to consult AskMayoExpert for care pathways outside of their specialty), asking them to use an external tool 100% of the time might work. But if the product/customer really wants something to happen, it may need to be more direct with clinicians in their inflection point. This is especially true if your product is taking on risk in demonstrating results. The flip side to this is ensuring that consideration is taken to avoid alert fatigue and false notifications to clinicians.
Conversely, if the goal of the product is to save clinician time then it should endeavor to do that completely. Going back to the “human scribes are the competition”, a better note writing tchotchke is less useful unless it is fully end-to-end. Even the friction of copy and paste may be too steep for a user to do for long-term. Can it work long enough for a clinician to validate that the tool is good? Probably. But probably also not tenable long-term.
How do you know if the model was effective?
Much like how feedback on a gift is important, knowing how the models are being used in production are important. If you make a recommendation, was it used? If you write a template for a note, how much was utilized? In many product analytics situations, you own all of this data but when push recommendations into the EHR you may need to ensure that you also know how those recommendations are acted on by ensuring the EHR can provide you information on use outside of the app. For example, if your application directly writes an Inbox message to a user in the EHR, how do you know if a clinician actually read it? Acted on it? The answers to these questions become complicated when you are operating within multiple domains.
I talked a bit in part one about how most health systems have no effective way to know if any given AI technology is good or not and how that will drive buying decisions. Yes, a model may make better decisions or be better trained than other models but seeing is actually believing. So, some health systems will buy models on blind faith or reputation. However, there will have to be proof that the metrics intended in use (time savings, provider satisfaction, revenue increase, productivity, etc.) are actualized in reality. The reasons for this are twofold:
It’s 2023 and the average health system now has a decent grasp of analytics on software usage. “Not negative feedback” is likely not good enough for any extended purposes.
The proliferation of LLM/AI tools means that other vendors are going to try similar circuitous methods to gain growth within a health system. If you sold to cardiologists and vendor X sold something to dermatologists there are going to be bakeoffs based on favorites based on price, cx and metrics. You want to ensure that you maintain stakes/proof when the CIO asks “why aren’t we just using the default Epic one?”” or “Derm LLM gave me a Yeti coozy”.
Wrapping up
This, of course, is all strategic in nature. The best way to see it in action is to build something up. Part 3 (which will be a bit more rapid) will dive into how to build and integrate some of our hypothetical bots/tools into clinical workflows.
Major thanks to Ben Lee and Tushar Parlikar for thoughtful pre-reads on this post.
We don’t do this, but this is basically the tension of every 90s sitcom.
I am not kidding, my former office abuts the parking lot of a mall. It is less bad than you would think it would be. We have a Clover!
If you are curious, it was a set of greeting cards and stationary with hand drawn images of a dog park.
The good news is that most of my traditional integration punching bags from five years ago have all mostly improved (good job having APIs Practice Fusion!) but there are still plenty of bad actors out there.
Or, if you want to think of it this way. Billing.
I recently spent time adding a variety of feature flexibility to the way by which we reported ultrasound reports, stemming from a previous assumption that there would be one true way by which we would send results and everyone would love them. I think if you have never worked in health tech, you may not appreciate the extent by which a lab, imaging or HIM director can totally mess your shit up if your documentation modeling does not meet their expectations for documentation for a given procedure or encounter. That’s not a criticism of them; in fact it is borne of their extremely intimate knowledge of where their organization has likely experienced massive blowbacks from either a regulatory, reimbursement or cultural standpoint. And they will likely be right unless your project stakeholder has a bigger stick and that will likely only be temporary. When you think about When/Where you should assume that you will need multiple tricks in the bag to be ultimately successful.
Thanks for Tushar for reminding me that I was being too midwestern about this and just calling it for what it is.
https://store.butterflynetwork.com/us/en/ please buy a probe. Rx only (USA). For use by qualified and trained healthcare practitioners.